・Facebook AIの研究者は、DD-PPOという名前の新しい強化学習アルゴリズムを開発しました。
・このアルゴリズムは、コンパスデータ、RGB-Dカメラ、GPSのみを使用して、複雑な環境においてのナビゲーションが可能です。
物理世界とスマートに対話する知能機械の開発は、AIコミュニティにおける長期の目標です。主な挑戦は、これらの機械が複雑でよく分からない環境で、地図を使わずに、効率的なナビゲートができるようにすることです。
通常、現実の世界地図は、構造の変化や物の移動によって、一か月以内には時代遅れのものとなります。よって、地図なしでナビゲート可能なAIの構築が、必要不可欠と言えるでしょう。
これらのことを念頭に置いて、Facebook AIの研究者は、コンパスデータ、RGB-Dカメラ、およびGPSのみを使用して、ポイントゴールナビゲーションタスクを効果的に解決する新しい強化学習(RL)アルゴリズムを開発しました。この大きなスケールのアルゴリズムは、DD-PPO(分散分散型の近位ポリシーの最適化)と名づけられました。
新しいRL分散アーキテクチャは、十分に拡張可能です
現在、機械学習ベースのシステムは、さまざまな複雑なゲームで人間の専門家を凌ぐ能力を備えています。しかし、これらのシステムが大量のトレーニングサンプルに頼るようになってからは、大規模な分散並列化なしでは、構築することが全く不可能になりました。
現在の分散強化学習アーキテクチャ(数千のワーカー(CPU)と単一のパラメーターサーバーを含む)は、適切に拡張できません。そのため、研究者は同期的な分散強化学習手法を提案しました。
DD-PPOは複数のマシンで実行されます。また、パラメーターサーバーはありません。各ワーカー(CPU)は、GPUアクセラレーション、リソース集約型のシミュレートされた環境でのエクスペリエンスの収集と、モデルの最適化を交互に行います。明示的な通信状態では、すべてのワーカーが更新をモデルに同期するでしょう。つまり、配布は同期的です。
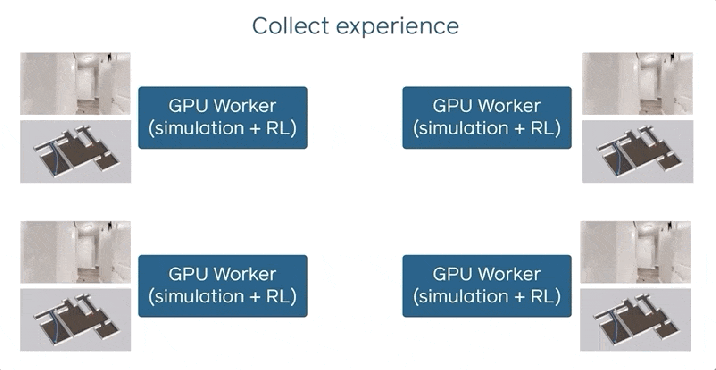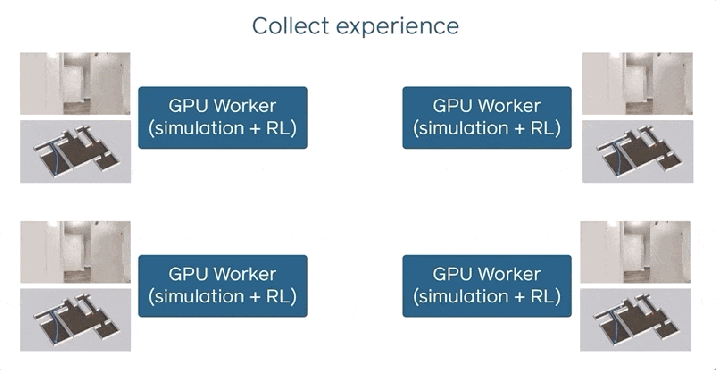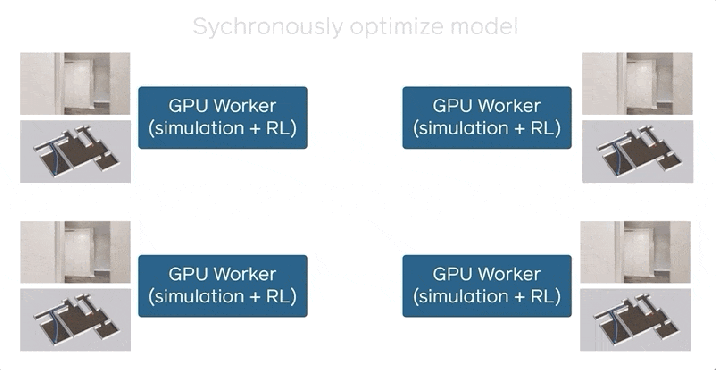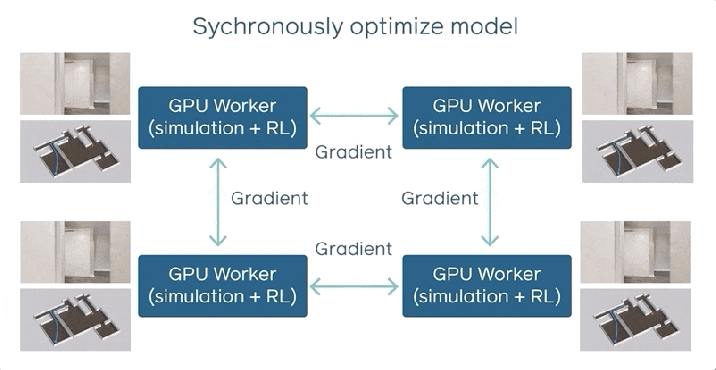
すべてのワーカーは、ポイントゴールナビゲーションを実行するエージェントをシミュレートし、モデルを最適化して更新を同期します。 これは、トレーニング中にDD-PPOでデータを共有する方法です
このアプローチを使用して、DD-PPOはほぼ線形のスケーリングを示しました。また、シリアル実装で128 GPUで107倍の高速化を達成できました。
ほぼ完璧なポイントゴールナビゲーション
ポイントゴールナビゲーションでは、エージェントはなじみのない環境でランダムな初期位置/方向に設定され、マップを使用せずにターゲット座標にナビゲートするよう、タスクが割り当てられます。また、コンパス、GPS、およびRGBカメラ、またはRGB-Dカメラのいずれかのみを使用できます。
研究者はDD-PPOのスケーリング機能を活用して、エージェントを25億ステップでトレーニングしました。これは、80年の人間の経験に相当します。トレーニングは、数か月ではなく3日以内に、64GPUで終了しました。
その結果、ピーク時のパフォーマンスの90%が、最初の1億ステップで、より少ないコンピューティングリソース(8 GPU)で得られたことが分かりました。数十億ステップの経験によって、エージェントは99.9%の成功率を得ることができました。対照的に、従来のシステムの成功率は92%となりました。

エージェントは、間違ったパスを選択して目標位置に到達した後、バックトラックします。
アプリケーション
これらのAIは、物理的な世界で人々をアシストすることができます。例えば、拡張現実眼鏡をかけているユーザーに関連情報を表示したり、ロボットが2階の机からアイテムを取り出したり、AIを搭載したシステムで、視覚障害のある人を支援することなどができます。
この調査で作成されたモデルは、追加のデータポイント(マップおよびGPSデータ)が利用できない実験室やオフィスビルなどの通常の設定で機能します。
このモデルは、ImageNetの事前トレーニングされたニューラルネットワークよりも優れており、ユニバーサルリソースとして機能します。しかし、複雑な環境をナビゲートすることを学習するシステムを開発するためには、やることはまだたくさんあります。研究者は現在、RGBのみのポイントゴールナビゲーションを実装するための、新しいアプローチを模索中です。