
















・DeepIMは、カラー画像のみを用いて物体の6次元姿勢を正確に推定する深層学習ベースのシステムである。
・深度画像【奥行きを記録した画像】を用いて姿勢を修正する最先端の手法を大幅に凌駕する。
実世界のいくつかのアプリケーションでは、標準的な画像から3Dで物体の位置特定を行う必要があります。例えば、バーチャルリアリティアプリでは、物体の6D姿勢(3D位置と3D向き)を認識できることで、人間と物体のバーチャルな交流が可能になります。ロボット工学においては、周辺にある物体を識別して移動させるために有用なデータを提供します。
最近開発された技術では、深度カメラを使って物体の6D姿勢を推定していますが、さほど正確ではありません。これらのカメラには、深度範囲、解像度、視野、フレームレートに関して、一定の制限があります。そのため、薄いもの、透明なもの、小さいもの、高速で移動するものを識別することができません。
物体の6D姿勢を推定するもうひとつの手法は、RGB画像を使用するものです。しかし、オクルージョン【手前にある物体が後ろにある物体を隠す状態】、状況の変化、姿勢の変化により、物体の外観が変化し続けるため、この手法も同様に困難です。また、このアルゴリズムでは、テクスチャのある物体とテクスチャのない物体の両方を維持する必要があります。
このたび、ワシントン大学、清華大学【中国】、NVIDIA【アメリカの半導体メーカー】の研究者たちが、カラー画像のみを用いて反復的な6D姿勢マッチングを行う、「DeepIM」【Deep Iterative Matchingの略、深層反復マッチングの意味】と名付けられた深層学習ベースのシステムを開発しました。
どのように機能するのか?
DeepIMは、物体の初期6D姿勢推定を使用して、相対ポーズ変換を提供します。これを初期姿勢に展開して6D姿勢推定を強化することができます。ディープニューラルネットワークは、学習しながら、徐々に物体の姿勢と一致するように学習していきます。
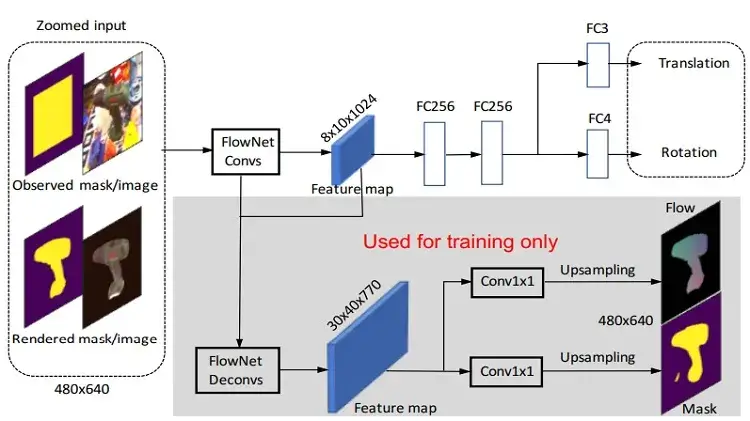
姿勢マッチングのためのネットワークアーキテクチャ
出典:研究チーム
DeepIMのアーキテクチャは、FlowNetSimple(画像ペア間のオプティカルフローを推定するために学習)とVGG16画像分類ネットワークに基づいています。入力から始まり、特徴マップは11の畳み込み層を通過します。これには、2つの完全接続層と、3D回転と3D並進の四元数【2次元平面の回転を表現する複素数の拡張として,3次元の回転を表現することができる】をそれぞれ推定するための2つの追加層が含まれます。学習中は、2つの補助枝がネットワークの特徴表現を制御し、学習の安定性を高めます。
学習戦略:研究チームは、各写真について、真実の姿勢に近いランダムな姿勢を10個作成し、学習データセットの各物体について2,000個の学習サンプルを形成しました。さらに、姿勢の分布が実際の学習セットと類似している個々の物体について、10,000枚の追加の合成画像を作成しました。したがって、すべての物体に対して、合計12,000個の学習用サンプルが用意されました。
このネットワークは、NVIDIA Tesla V1000 GPUとMXNetframeworkを用いて、数千枚の画像(LINEMODデータセットから取得)で学習されます。
研究チームはまた、3D物体の座標フレームに依存しない、もつれの無い姿勢表現も開発しました。これにより、DeepIMはさらに進化し、ニューラルネットワークは未知のアイテムの姿勢を照合することができるようになりました。
カラー画像のみを使用したこの技術は、6D姿勢推定の最先端アプローチを大幅に凌駕しています。その結果は非常に印象的で、その性能は、深度画像を使用して姿勢を洗練させる手法である反復的最接近点アルゴリズムに似ています。
活用
DeepIMは様々な用途に活用できます。例えば、この手法のステレオ版では、姿勢の精度をさらに向上させることができます。また、カラー画像のみで正確な6次元姿勢推定を行うことができるため、バーチャルリアリティやロボット操作などの用途で、詳細かつ有用な推定を提供することができます。





