
















・新しいディープラーニングモデルのMelNetは、超人的な正確性で人間の抑揚を生み出すことができます。
・一度訓練されれば、2、3秒でどんな人の声でも再生することが可能です。
・調査員たちはどのくらいの精密度でビル・ゲイツの声を再現できるか実演しています。
ここ数年で、機械が学ぶ技術には大きな利点が見られてきました。これらの技術は、物体や顔を認識したり、現実的な画像を生み出したりするのにとても優れているからです。
しかし、音声となると、人工知能には失望が続いています。最も有能な読み上げ機能のシステムでさえも、抑揚の変化など基本的な特徴に欠けているのです。スティーブン・ホーキングの機械再生の声を聞いたことがあるでしょうか?時々、彼の文を理解するのはとても難しいと感じてしまいます。
今日、フェイスブックでのAI調査は、読み上げ機能での限界を乗り越える方法を開発しました。生産可能なモデルを製作したのです―名前はMelNet―超人的な正確性で人間の抑揚を生み出すことができます。実は、誰の声でも流暢に話すことができるのです。
これまでの機械音声との違いは何か
一番のディープラーニングアルゴリズムは、実際の話し言葉のパターンを生み出すため、巨大なオーディオデータベースを基に訓練されています。この方法論での主な問題は、データの種類です。典型的に、これらのアルゴリズムはオーディオ波形の録音により訓練されていて、劇的に異なるタイムスケールで、複雑な構成を持っています。
これらの録音は、時間と共に音の振幅が異なる様子を表しています:一秒間のオーディオは何万ものタイムステップを含んでいるのです。このような波形は、異なるスケールの数字で特定的なパターンに反映しています。
すでに存在する波形の生産モデル(SampleRNNやWaveNet)は、一秒間のほんの少しを通してしか逆方向伝導できないのです。ですから、7秒間スケール上に現れる高レベルの構成を捉えることはできません。
MelNetは逆に、スペクトログラム(オーディオ波形の代わりに)を使い、ディープラーニングネットワークで訓練します。スペクトログラムは2Dの時間周波数表現であり、オーディオ周波数のスペクトラム全体とそれが時間と共に異なる様子を示しています。
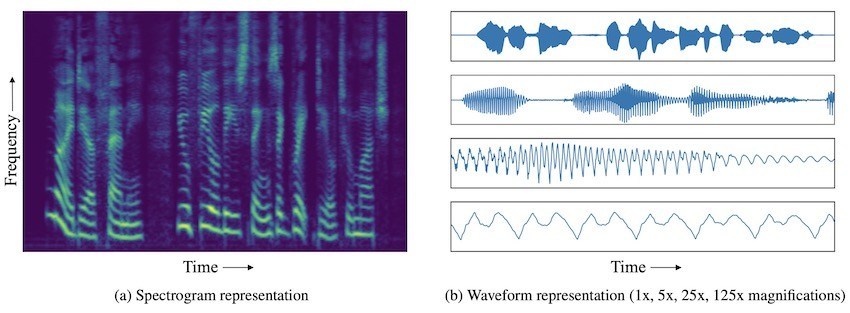
1Dの時間領域波形が、一つの変数(振幅)の時間に対する変化を捉える中、スペクトログラムは異なる振動に対する変化を捉えます。結果として、オーディオ情報はスペクトログラムに密集してより詰め込まれているのです。
これは、MelNetが無条件のスピーチと、数分で一貫性のある音楽サンプルを生み出すことを促しています。また無条件での音声生産と、最初から最後までの読み上げ総合体を可能としています。
情報提供:arXiv:1906.01083 | GitHub
情報ロスを減らし過剰な平滑化を制限するため、彼らは高解像度のスペクトログラムを形成し、それぞれに表現豊かな自己回帰モデルを使いました。
優れた制作例の数々
調査員たちはMelNetを数々のTed Talkで訓練し、次には数秒にわたり話し手の声が話すフレーズを再生することに成功しました。以下、MelNetがビル・ゲイツの声を使ったランダムなフレーズの2つの例です。
Facebook Develops AI Capable of Copying Anyone’s Voice With Unprecedented Accuracy – RankRed
“ポートはスモーキーな味の力強いワインだ”
Facebook Develops AI Capable of Copying Anyone’s Voice With Unprecedented Accuracy – RankRed2
“イベントが暗転すると私たちも顔をしかめてしまうよ”
GitHubではより多くの例を紹介しています。
MelNetは素晴らしく人間に近いオーディオクリップを生産できますが、長めの文や文章を生み出すことはできません。どちらにしても、このシステムはコンピューターと人間のやり取りをより改善してくれるでしょう。
カスタマーケアでの多くの会話は短いフレーズを含みます。MelNetはそのようなやり取りを自動化し、電話での会話体験を向上するためにも、現在の自動音声システムと入れ替えるために活用されるべきなのです。
読んでみてください:フェイスブックAIが音楽のスタイルを変換する
マイナス面としては、この技術で偽のオーディオコンテンツによる新しい時代スペクトルが掲げられることでしょう。またその他の人工知能の利益からも見られるように、そのAIが答えられる内容を超えた、倫理的な質問が表面化してくると考えられます。





