

















ここMozでは、特にウェブをクロールする方法で、できるだけGoogleに類似した、LinkExplorerを作成することに力を入れています。以前の記事では、パフォーマンスを確認するために使用したいくつかの指標について説明しましたが、今日はrobots.txtの影響とWebクローリングについて説明することに少し時間を割きたいと思います
ほとんどの方は、ウェブマスターがGoogleや他のボットにサイトの特定のページだけを訪問させる方法であるrobots.txtのことをよくご存じの事と思います。ウェブマスターは、特定のボットにいくつかのページを訪問させ、また他のボットへのアクセスを拒否することができます。これはMoz、Majestic、Ahrefsなどの企業にとって問題です。GoogleのようにWebをクローリングしようとしても、特定のWebサイトではGooglebotへのアクセスは許可されていても私たちのボットのアクセスが拒否されることがあります。でも、これが問題となる真の理由は何なのでしょうか。
何が深刻な問題なのか
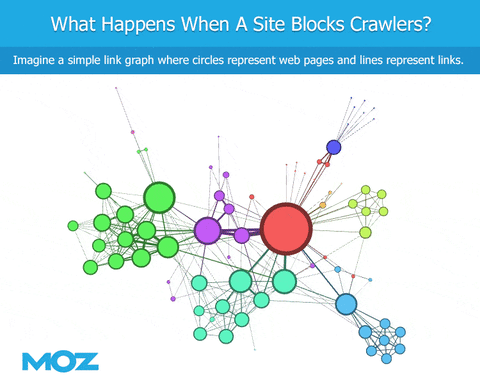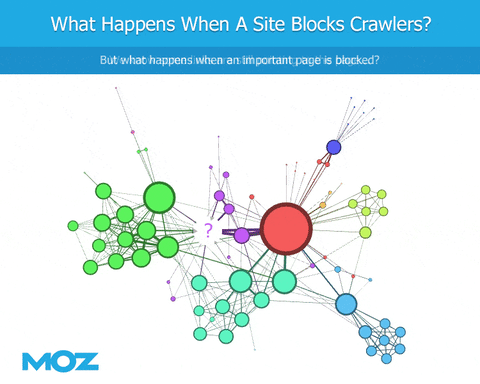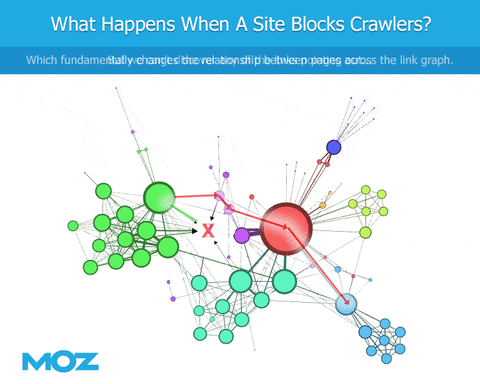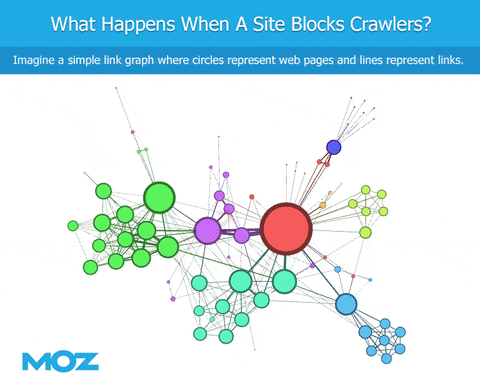
クローリングを行う際、ボットがrobots.txtファイルに遭遇すると、特定のコンテンツのクローリングがブロックされます。サイトを指しているリンクを見ることができますが、サイト自体の内容までは分かりません。そのサイトからのアウトバウンドリンクも表示されません。これは、少なくともGoogleとの類似を目指す点では(Googlebotが同様にブロックされていない場合)、リンクグラフが突然不足することにつながるため問題です。
しかしそれだけではありません。 robots.txtによってボットがクローリングの優先順位付けの形式でブロックされているため、連鎖的に障害が発生します。ボットはWebをクローリングするので、リンクを検出し、次にクロールするリンクの優先順位を決定する必要があります。Googleが100のリンクを見つけ、トップ50のクローリングを優先させるとしましょう。ここで、別のボットも同じ100のリンクを見つけますが、robots.txtは上位50ページのうち10ページのクローリングからブロックされてしまいます。代わりに、別の50ページをクローリング対象として選択させられてしまうのです。このクローリングされた一連の異なるページは、もちろん、異なるリンクセットを返します。次のクローリングでは、Googleはクローリングが許可されている異なるセットを持っているだけでなく、最初に別のページをクローリングしたために、そもそもセット自体が異なるのです。
端的にいえば、諺にある、羽ばたきが最終的にハリケーンを引き起こすことになる蝶のように、特定のボットをブロックし、その他を通過させるようなrobots.txtは最終的にGoogleが実際に見ているものとは非常に異なる結果に繋がるのです。
ではどう対処するか
ただ黙って見ていなさいというつもりはないことはもうお分かりでしょう。ちょっと調査をしてみましょう。Quantcastに従ってインターネット上の上位100万のウェブサイトを分析し、どのボットがブロックされているのか、どのぐらいの頻度でどのような影響があるかを判断しましょう。
方法
方法はとても簡単です。
1.Quantcast Top Millionをダウンロードする。
2.入手可能であればサイトからrobots.txtをダウンロードする
3.robots.txtを解析して、ホームページや他のページが利用可能かどうかを判断する
4.ブロックされたサイトに関連するリンクデータを収集する
5.ブロックされたサイトに関連するオンサイトの全ページを収集します。
6.クローラ間の違いをリポートまとめる
ブロックされたサイトの総数
報告する最初の最も簡単なメトリックは、個々のクローラ(Moz、Majestic、Ahrefs)をブロックする一方でGoogleを通過させるサイトの数であり、主要なSEOクローラのどれか1つをブロックするほとんどのサイトがそういったクローラをすべてブロックしています。彼らは単にrobots.txtを策定して、他のボットトラフィックをブロックしながら主要な検索エンジンのボットを許可しています。値が低い方が好ましいです。
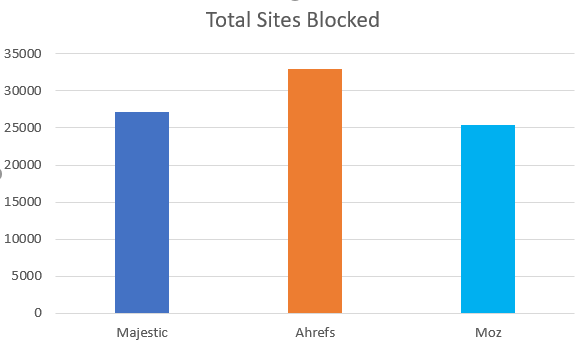
分析されたサイトのうち、27,123がMJ12Bot(Majestic)をブロックし、32,982がAhrefsをブロックし、25,427がMozをブロックしていました。これは、主要な業界クローラの中で、MozがGooglebotを許可するサイトから締め出されてしまう可能性が最も低いことを意味します。しかし、これは何を意味しているのでしょうか。
ブロックされた総RLD
以前に説明したように、本質的に異なるrobots.txtエントリの大きな問題の1つは、ページランクの流れを止めてしまうことにあります。 Googleがサイトを閲覧することができれば、参照ドメインのリンク資産をサイトのアウトバウンド・ドメインを通じて他のサイトに渡すことができます。サイトがrobots.txtによってブロックされている場合は、サイトに入るすべての道路のアウトバウンド側車線がブロックされているような状態になります。受信トラフィックのすべてのインバウンドレーンを数えることによって、リンクグラフへの全体的な影響を知ることができます。値が低い方が好ましいです。
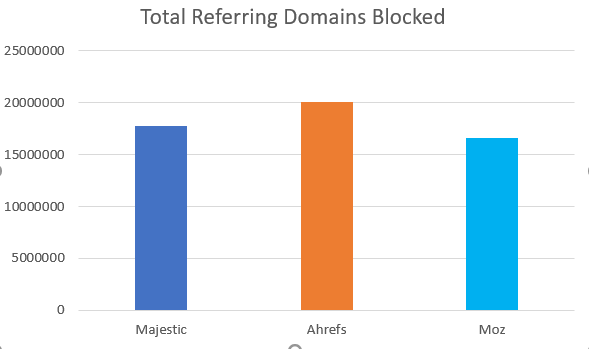
私たちの調査によると、Majesticは、17,787,118、Ahrefsは20,072,690、Mozは16,598,365の参照ドメインで行き止まりになっていました。繰り返しになりますが、Mozのrobots.txtプロファイルはGoogleのプロファイルと最もよく似ていました。しかし、私たちが関心を持つべきなのは参照ドメインのみではありません。
ブロックされた総ページ数
ウェブ上のほとんどのページには内部リンクしかありません。 Googleはリンクグラフの作成ではなく、検索エンジンの作成に関心があります。したがって、Googleのように振る舞うように設計されたボットは、外部リンクを受けているページと同じように内部リンクだけを受けているページを取り扱わなければなりません。 測定できるもう1つの指標は、Googleのサイトを使用してブロックされたページの総数です。つまり、Googleがアクセスでき、他のクローラにはアクセスできないページ数を見積もるのです。では、この業界で競合する各社のクローラの機能はどうでしょうか。この値も低い方が好ましいです。

再び、Mozはこの指標で比べた時にも輝いています。 Mozはブロックされているサイトが少ないだけではありません。Mozをブロックしているのは、あまり重要ではない、小さいサイトなのです。 Majesticは、675,381,982ページ、Ahrefsは732,871,714、Mozは658,015,885のページをクロールするチャンスを逃しています。 AhrefsとMozの間には、Web上の閲覧者数ランキング上位のサイトだけで8000万ページの違いがあります。
ブロックされたサイトの種類
Moz、Majestic、そしてAhrefsを拒否するrobots.txtのほとんどは、ボットを毛布で包んでしまい、一様に主要な検索エンジンの検索結果を示せなくなるだけです。しかし、特定のボットの名前が意図的に除外され、競合他社がクローリングを許されている回数を特定することはできます。たとえば、AhrefsとMajesticがクローリングを許可されている時にMozがブロックされた回数はどのぐらいでしょうか。どのボットがもっとも仲間外れにされやすいのでしょうか。値は低い方が良いです。
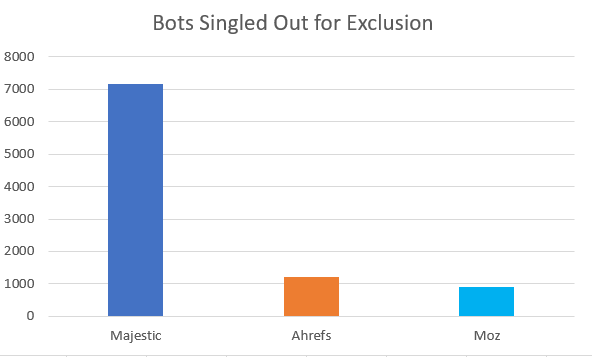
Ahrefは1201のサイトで、Majesticは7152、Mozは904のサイトで仲間外れになっています。Majesticは、10年以上の長きにわたり、非常に大きなリンクインデックスを運用してきたことを考えると、仲間外れになりやすい理由は理解できます。 Mozは904のrobots.txtブロックを蓄積するのに10年かかっています。そして、Ahrefは1204のrobots.txtブロックを累積するのに7年間を費やしました。なぜこのことが重要なのか、例を挙げて説明しましょう。
name.com、hypermart.net、またはeclipse.orgからのリンクに関心があるなら、Majesticだけを頼りにしてはいけません。
popsugar.com、dict.cc、またはbookcrossing.comからのリンクに関心があるなら、Mozだけを頼りにしてはいけません。
dailymail.co.uk、patch.com、getty.eduからのリンクに関心があるなら、Ahrefsだけを頼りにしてはいけません。
目的や使っているプロバイダーに関係なく、yelp.com、who.int、findarticles.comからのリンクは把握できません。
結論
MozillaのクローラDotBotは3つの主要なリンクインデックスの中でGoogleに最も似た方法でrobots.txtに反応できることは明らかですが、まだ行わなければならない作業がたくさんあります。私たちはウェブマスターに負担を与えないことを保証し、よりGoogleのようなクローリングを可能にするために、クローラをより礼儀正しく振る舞わせるための努力を重ねています。ウェブ上でのパフォーマンスを向上させ、可能な限り最良のバックリンク・インデックスを提供するために、引き続き改良をつづけていきます。
ヘッダー画像に用いられている美しいリンクグラフを提供してくださったDejan SEO、図で使用される最初の画像を提供してくださったMaptに感謝の意を申し上げます。
※本記事は、Backlink Blindspots: The State of Robots.txtを翻訳・再構成したものです。
▼こちらの記事もおすすめです!








